Bij het ontwerp en beheer van drinkwaterdistributieleidingnetten is het gebruik van leidingnetberekeningspakketten (vroeger Aleid, nu InfoWorks WS, Synergee, Epanet) sinds 25 jaar gemeengoed bij de waterleidingbedrijven. Bij het opstellen en analyseren van hydraulische netwerkberekeningen komen veel data van een drinkwaterbedrijf samen. Hoe snel en volledig het mogelijk is hydraulische pakketten in te zetten voor analyses, hangt af van zowel de kennis over de pakketten als de beschikbaarheid van data. Op beide vlakken is de laatste jaren nogal wat beweging geweest. Dit heeft geleid tot nieuwe inzichten en methoden.
Bij de huidige generatie van de pakketten is een duidelijkere relatie te zien met de GIS (Geografisch Informatie Systeem)-pakketten. Grafisch zijn de pakketten sterk en de analysemogelijkheden in de software zijn toegenomen. Om hier optimaal gebruik van te kunnen maken zijn aanzienlijke hoeveelheden data vanuit de organisatie nodig, en worden er eisen gesteld aan de kwaliteit van deze data. Daarnaast kunnen er alleen betekenisvolle resultaten met deze software worden verkregen, als de mensen die hem gebruiken voldoende begrip en inzicht hebben in de software en in de processen zelf.
De nieuwe generatie software maakt het mogelijk om een diversiteit aan vraagstukken door te rekenen en de resultaten op vele manieren te presenteren. Hierdoor zijn de uitkomsten inzichtelijk te maken voor een breed publiek.
Nu deze mogelijkheden beschikbaar zijn, wil men ze ook gebruiken. Vanwege de complexiteit van de software is het een uitdaging voor de expert om dit op de juiste en de meest efficiënte manier te doen.
Een leidingnet bevat honderdduizenden leidingen. Van elk van deze leidingen worden parameters als materiaal, lengte, diameter, etc. opgenomen in een model. Naast deze informatie worden data verwerkt over vraagpatronen, voedingen, sturingen, etc. Het opbouwen van een model bestaat uit het combineren van miljoenen informatie-elementen. De bron van veel van deze informatie is in sommige gevallen al vele jaren oud (bijvoorbeeld gedigitaliseerd analoog kaartmateriaal) en kan dus ook fouten bevatten. Een deel van deze fouten kan worden opgelost met behulp van geautomatiseerde controles op interne consistentie en dergelijke. Het is echter onmogelijk om al deze informatie met 100% betrouwbaarheid te controleren, en we moeten ons dus realiseren dat er mogelijk fouten in de gebruikte informatie zitten.
Met het toenemen van de mogelijkheden en het aantal beschikbare gegevens neemt bij de gebruiker (of analist) echter ook de onzekerheid over de verkregen resultaten toe. Met dit artikel beogen wij het bestaan van deze paradox te illustreren. Wij willen de problematiek duidelijk maken, niet alleen voor de analisten, maar vooral ook voor diegenen bij drinkwaterbedrijven die gebruik maken van de rekenresultaten.
Benodigde kennis
De essentie van het leidingnetmodel is weergegeven in afbeelding 1. Hierin staan de drie basiselementen, namelijk de voeding (productielocaties, bergingslocaties, overdrachtspunten), het leidingnet en het verbruik (huishoudens, kleinzakelijk verbruik, en grootverbruik). In de regel is het aantal voedingen beperkt tot maximaal enkele tientallen. Een leidingnet bestaat al snel uit honderdduizenden elementen. Het aantal verbruikspunten kan tot in de miljoenen lopen, waarbij iedere verbruiker in ieder geval in de praktijk een eigen, uniek vraagpatroon heeft. De modelleur/analist moet begrip en overzicht hebben van een aantal aspecten:
• regeling van voedingen;
• bedrijfsvoering van het netwerk (schakeling, afsluiters, etc.);
• verbruikspatronen voor verschillende groepen verbruikers onder verschillende omstandigheden (jaargetijde, etc.);
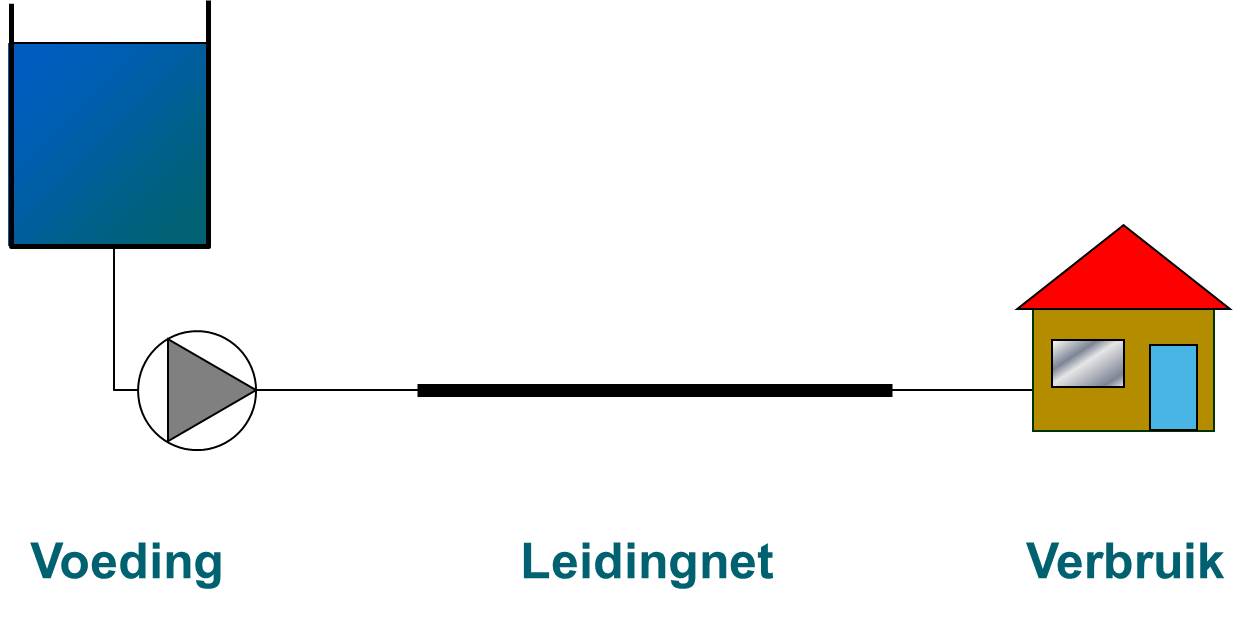
Afbeelding 1. Schematische weergave van een leidingnetmodel
Bovendien moeten de modelbouwer en de modelgebruiker beschikken over informatie over de beschikbaarheid en het format van data binnen het bedrijf en van de mogelijkheden deze (direct) te koppelen aan het model. Alleen dan is het mogelijk deze efficiënt in het model te incorporeren. Gegevens kunnen echter niet zonder meer in een model worden opgenomen. Een van vele denkbare voorbeelden is de import van leidinggegevens uit een LIS (Leiding Informatie Systeem). In een LIS is de hydraulische connectiviteit van leidingen niet altijd relevant; voor een hydraulisch model is deze echter essentieel. De analist neemt de verantwoordelijkheid voor dergelijke controles en aanpassingen.
Het goed uitvoeren van hydraulische modelberekeningen vereist kennis van de fysische processen, de modelmogelijkheden en de gebruikte rekenmethodieken. Alleen dan is het mogelijk de betekenis van de resultaten op waarde te schatten. De software is dus niet als black box te gebruiken. De modelsoftware bevat daarnaast vele hulpmiddelen om het werk aan zowel de invoerzijde als de uitvoerzijde te vergemakkelijken. Vaardigheden met betrekking tot GIS-pakketten, het schrijven van slimme query’s (zoekopdrachten binnen een database) en het programmeren van sturingen met behulp van de beschikbare tools binnen de programmatuur zijn essentieel. Om deze competenties te ontwikkelen is veel rekenervaring nodig; bij elke nieuwe uitdaging wordt weer een nieuwe stap gezet in de kennis over hoe je het beste om kunt gaan met de programmatuur.
Het feit dat het mogelijk is een leidingnet gedetailleerd door te rekenen betekent niet automatisch dat dit altijd nodig is en/of wordt gedaan. Op sommige vragen volstaat een grover antwoord dan op andere. De analist heeft hierbij de keuze om, op basis van eigen inzicht en ervaring, het antwoord op een bepaald detailniveau te bepalen (zie ook kader).
Vertrouwen in de uitvoer
In eerste instantie stoelt vertrouwen in de uitvoer op vertrouwen in alle aspecten die in de voorgaande paragraaf zijn behandeld. Hierbij hoort ook een validatie, waarin rekenresultaten worden vergeleken met gemeten waarden (bijvoorbeeld voor druk en/of volumestroom) voor een specifieke situatie. Ook dit vereist de nodige kennis en expertise en moet zorgvuldig gebeuren.
De manier waarop processen en hun onderlinge afhankelijkheden in de simulatiesoftware zijn geïmplementeerd, heeft gevolgen voor de resultaten van de simulaties. Een voorbeeld hiervan is weergegeven in afbeelding 2. Hierin wordt de berekende druk op een voeding in een hydraulisch model weergegeven in blauw en roze, de gele punten geven de gemeten druk weer. De berekening is uitgevoerd over een periode van twee dagen. Bij de blauwe en roze resultaten is de invoer gelijk, maar is er een verschil in de ingestelde nauwkeurigheid van de sturing op het regelelement. Hiermee ontstaan verschillen in het gedrag van het betreffende element waar de modelgebruiker zich van bewust moet zijn. Vooral gedurende de tweede dag treden er hierdoor in het model afwijkingen op in de schakeltijdstippen (rond 6 uur en 21 uur).
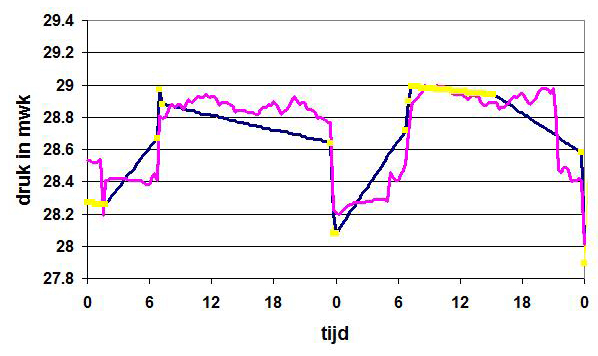
Afbeelding 2. Voorbeeld van verschillende uitkomsten voor de schakeltijdstippen bij gelijke modelinvoer met verschillende instellingen voor de sturingsnauwkeurigheid van een individueel regelelement.
Bestaat de informatieparadox?
Hoe meer informatie je kunt verzamelen, hoe duidelijker het wordt dat je bepaalde dingen niet (zeker) weet. Als de analist weet welke kwaliteit van informatie wordt gebruikt, hoe deze verwerkt wordt, welke marges de uitkomsten hebben en welke marges zijn toegestaan, dan bestaat deze informatieparadox niet. Aangezien de modellen echter erg complex zijn, kan de analist helaas niet alles weten, en daarmee is de paradox een feit. Iets om rekening mee te houden! Maar de analisten zijn wel bij uitstek degenen die de onzekerheid in het gegeven antwoord op de gestelde vraag kunnen inschatten, en daarmee de paradox kunnen beheersen. Onderlinge uitwisseling van ervaringen en informatie, bijvoorbeeld in het kader van de Platformgroep Leidingnetmodellen, maakt dit mogelijk.
















Een interessant gegeven is dat 80% van ons drinkwater thuis wordt verbruikt. Daar ligt een enorme uitdaging, maar ook een kans om echt verschil te maken. Door slimmer om te gaan met de distributie van water, kunnen we helpen om het verbruik te verminderen zonder dat we daar veel van merken. Dit zou niet alleen helpen om onze waterbronnen te sparen, maar ook de druk op het systeem tijdens droge perioden verlagen.
Dit gaat verder dan alleen maar korter douchen; het gaat om een bewuste verandering in ons dagelijks leven om ervoor te zorgen dat er genoeg water is voor iedereen. Iemand iets gunnen. Beginnen met het nadenken over de oplossingen menukaart ook met water zoals we dat met energie doen - waar kunnen we besparen, hoe kunnen we efficiënter zijn, en hoe kunnen we ons aanpassen aan nieuwe omstandigheden?
Er is geen eenduidige oplossing voor het probleem, en additionele productie levert ons op langere termijn niets op. Misschien is het tijd om deze uitdaging aan te gaan en te kijken naar hoe we thuis ons watergebruik kunnen optimaliseren.